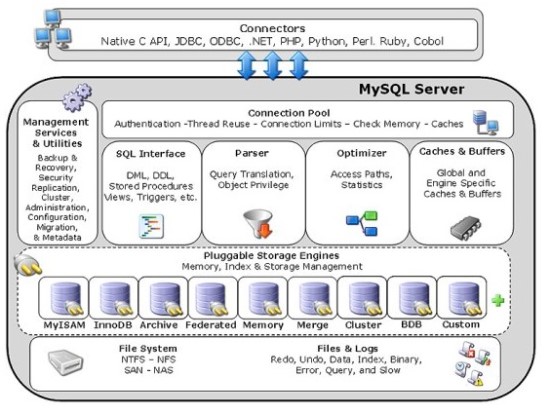
In the MySQL stored procedure language, handlers can be written to handle the occurrence of some condition. Typically, handlers are used to handle error conditions.
Error conditions are conveniently declared by referring to some predefined class of conditions (e.g. NOT FOUND), or by specifying a particular SQLSTATE. Also, a "catch-all-others" condition is predefined (SQLEXCEPTION), in order to handle those errors for which no appropriate handler is in scope.
However, when handling such a general error condition, MySQL stored procedures do not provide any means to discover the nature of the error condition. If one would want to log the occurrence of the error, there is no way of logging the current value of SQLSTATE from within the stored procedure layer. One is forced to do this from the application layer, which seems to be the wrong place to do this.
Other major dbms-es have solved this by exposing the current errorcode and (sometimes message) in a global variable (@@ERROR for MSSQL, SQLCODE and SQLERRM for Oracle). The ANSI Standard also suggests a command to discover the nature of an error condition by using the GET DIAGNOSTICS command (although it is not clear to me in what form the information would become available in the context where diagnostics are requested).
How to repeat:
NA
Suggested fix:
Expose SQLSTATE or something similar (like C API mysql_error()) as a global variable or function from within the context of stored procedures so that we could write:
declare exit handler for sqlexception
insert into error_table (
code
, message
) values (
@@SQLSTATE
, @@SQLSTATE_MESSAGE
)
========================================================================
DELIMITER $$
DROP PROCEDURE IF EXISTS `sp_Test` $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_Test`()
body:
BEGIN
DECLARE err_key INT DEFAULT 0;
CREATE TEMPORARY TABLE T1 (ID INT, Name VARCHAR(250));
CREATE TEMPORARY TABLE T2 (ID INT, Name VARCHAR(250));
SET AUTOCOMMIT=0;
START TRANSACTION;
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET err_key=1;
DECLARE EXIT HANDLER FOR SQLWARNING SET err_key=2;
INSERT INTO T111
SELECT Source_ID_In, Master_Company_Name_in
FROM htn.jigsaw_temp limit 1,10;
INSERT INTO T1
SELECT Source_ID_In, Master_Company_Name_in
FROM htn.jigsaw_temp limit 11,30;
INSERT INTO T1
SELECT Source_ID_In, Master_Company_Name_in
FROM htn.jigsaw_temp limit 31,40;
END;
IF err_key = 1 THEN
ROLLBACK;
SELECT 'SQL EXCEPTION ERROR';
SELECT perror;
DROP TABLE T1;
DROP TABLE T2;
leave body;
END IF;
IF err_key = 2 THEN
ROLLBACK;
SELECT 'SQL WARNING ERROR';
DROP TABLE T1;
DROP TABLE T2;
leave body;
END IF;
SELECT * FROM T1;
DROP TABLE T1;
DROP TABLE T2;
COMMIT;
END $$
DELIMITER ;
외.... 참고....http://cafe.naver.com/life4we/45