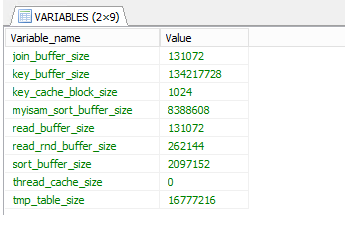
- ASCII(str) : 해당 인저의 아스키 값을 반환한다. 문자열이 한글자 이상일 경우는 첫번째 문자에 해당하는 아스키 값을 반환한다.빈 문자열에 대해서는 0, NULL 에 대해서는 NULL을 반환한다.
- 예 : selectASCII('2');
- CONCAT(X,Y,...) : 해당 인자들을 연결한 문자열을반환한다. 인자중 하나가 NULL 일 경우는 NULL 을 반환한다.
- 예 : selectCONCAT('My', 'S', 'QL');
- LENGTH(str) : 문자열의 길이를 반환한다.
- 예 : selectLENGTH('text');
- OCTET_LENGTH(str) : LENGTH(str) 와 동일하다.
- CHARACTER_LENGTH(str) : LENGTH(str) 와동일하다.
- LOCATE(substr,str) : 첫번째 인자에서 두번째 인자가있는 위치를 반환한다. 없을경우 0 을 반환한다.
- 예 : selectLOCATE('bar', 'foobarbar');
- POSITION(substr IN str) :LOCATE(substr,str) 와 동일하다.
- LOCATE(substr,str,pos) : 두번째 인자에서 세번째인자의 자리수부터 검색을 하여 첫번째 인자가 발견되는 위치를 반환한다.
- 예 : selectLOCATE('bar', 'foobarbar',5);
- INSTR(str,substr) : LOCATE(substr,str) 와동일한 기능을 하며, 차이점은 첫번째 인자와 두번째 인자가 바뀐것 뿐이다.
- 예 : selectINSTR('foobarbar', 'bar');
- LPAD(str,len,padstr) : 첫번째 인자를 두번째인자만큼의 길이로 변환한 문자열을 반환한다. 모자란 공간은 왼쪽에 세번째 인자로 채운다.
- 예 : selectLPAD('hi',4,' ');
- RPAD(str,len,padstr) : LPAD 와 반대로 오른쪽에빈공간을 채운다.
- 예 : selectRPAD('hi',5,'?');
- LEFT(str,len) : 첫번째 문자열에서 두번째 길이만큼만을반환한다.
- 예 : selectLEFT('foobarbar', 5);
- RIGHT(str,len) : LEFT(str,len) 와 동일하다. 차이점은 해당 길이만큼 오른쪽에서부터 반환한다.
- 예 : selectRIGHT('foobarbar', 4);
select SUBSTRING('foobarbar' FROM 4);
- SUBSTRING(str,pos,len) : 첫번째 인자의 문자열에서두번째 인자의 위치부터 세번째 인자의 길이만큼 반환한다.
- 예 : selectSUBSTRING('Quadratically',5,6);
- SUBSTRING(str FROM pos FOR len) :SUBSTRING(str,pos,len) 과 동일하다.
- MID(str,pos,len) : SUBSTRING(str,pos,len)과 동일하다.
- SUBSTRING(str,pos) : 첫번째 인자의 문자열에서두번째 인자로부터의 모든 문자열을 반환한다.
- 예 : selectSUBSTRING('Quadratically',5);
- SUBSTRING(str FROM pos) :SUBSTRING(str,pos) 와 동일하다.
- SUBSTRING_INDEX(str,delim,count) : 첫번째인자인 문자열을 두번째 문자로 구분하여 세번째 인자 수의 위치만큼 반환한다. 예를들어 select SUBSTRING_INDEX('www.mysql.com', '.', 2) 은 'www.mysql' 을 반환한다. 세번째 인자가 음수일경우는 반대로오른쪽에서부터 검색하여 결과를 반환한다.
- 예 : selectSUBSTRING_INDEX('www.mysql.com', '.', -2);
- LTRIM(str) : 왼쪽에 있는 공백문자를 제거한 문자열을반환한다.
- 예 : select LTRIM('barbar');
- RTRIM(str) : 오른쪽에 있는 공백문자를 제거한 문자열을반환한다.
- 예 : selectRTRIM('barbar ');
- TRIM([[BOTH | LEADING | TRAILING][remstr] FROM] str)
- 예 : select TRIM('bar ');
select TRIM(LEADING 'x' FROM 'xxxbarxxx');
select TRIM(BOTH 'x' FROM 'xxxbarxxx');
select TRIM(TRAILING 'xyz' FROM 'barxxyz');
- REPLACE(str,from_str,to_str) : 문자열은치환한다.
- 예 : selectREPLACE('www.mysql.com', 'www', 'ftp');
- REVERSE(str) : 문자열을 뒤집는다. 예를들어, select REVERSE('abc') 은 'cba' 를 반환한다.
- LCASE(str) : 문자열을 소문자로 변환한다.
- 예 : selectLCASE('QUADRATICALLY');
- LOWER(str) : LCASE(str) 와 동일하다.
- UCASE(str) : 문자열을 대문자로 변환한다.
- 예 : selectUCASE('Hej');
- UPPER(str) : UCASE(str) 와 동일하다.